On Developing an Application for Inferring MSS Foliation
Some Background on Manuscript Folio and Page Enumeration
From the perspective of a manuscript digitization team, one of the most important pieces of information to collect prior to imaging is a comprehensive account of the artifact’s numbering. By “numbering,” I mean that thing often written on the top or bottom right of the recto side of each folio.
These foliation markers are most often written in pencil using Arabic numerals. They are the result of past researchers or archivists. While today’s manuscript researchers and conservators would balk at the idea of marking up an ancient document, I must admit that the decision of others in recent centuries to enumerate folios or pages has made it easier for us to navigate and cite these volumes.
In my experience, New Testament Greek Manuscripts are normally foliated: each recto is enumerated. This means that there is a front and back to each number (recto and verso). But some manuscripts are paginated instead, i.e., the recto and verso of the same folio receive different numbers. Pagination almost always begins with “1” on the recto (for left-to-right scripts). It is also common for a manuscript to be paginated yet only contain a numeral on the recto. In this situation, it is practically foliated, but each page (side of the folio) is included in the enumeration. I.e., the number on the recto increases by 2 for each recto.
The Importance of Foliation/Pagination for Digitization
During imaging, these written numerals are an ideal way of ensuring that pages are not skipped or doubled during imaging. It is an easy thing for the manuscript handler to turn two pages by accident. This is especially true of parchment manuscripts in which the folia often differ greatly concerning the thickness of a single folio. Ideally, at any point, the imaging team should be able to note that they are about to take, for example, image “223,” which should correlate to one folio or page number in the manuscript. If the count is off, then the team can pause and correct the error (almost always a missed page).
The Problem
It is rare that handwritten manuscripts are foliated or paginated correctly. In my experience, one in five have no numbering errors. Common errors include the accidental skip (perhaps because two folia have clung together), writing the same number twice in a row, and going back by ten (e.g. going back to “210” after reaching “220”).
The imaging needs a complete account of the written numbers and the errors so that they can keep close track of what has been imaged and what should be imaged at any given point. Obviously, if there are no mistakes, then one need only look at the number written on the first and last folios and infer the intervening numbers. But this is rarely possible.
Numeration Reconciliation
This leads me to a piece of software that I developed for inferring the complete foliation and pagination of error-riddled books with the most minimal input necessary.
The traditional method of noting numeration mistakes is to keep track of a running correct number and coordinate the written number with the corrected one. Such notations usually look like this: 9=10, 15=15, 123=125, etc.
This method can become entirely indecipherable when there are many mistakes and there is mixed foliation and pagination within the same set of bound material. I encountered this several times in the Greek New Testament manuscripts held by Lambeth Palace Library in London.
In my method, I have the concept of a “landmark,” that is, the thing written on the page, and the “actual,” the corrected number. The traditional method of numeration reconciliation requires the cataloguer to track both the landmark and the actual. My method, however, only tracks the landmark and then the software infers the actual.
My Method
- Landmarks and “Numbering Types” are recorded in groups.
- There are three basic types that each group is assigned to:
- Unnumbered: no number is written on the folio.
- Foliated: the group of folia have landmarks written on each of them.
- Paginated: the group of folia are paginated.
- Everything is actually a folio.
- When entering page numbers, it must be stated whether the number on the recto is odd or even. If the number is odd, then the input range must begin with an odd number and end with an even number. If the number on the recto is even, then the input range must begin with an even number and end with an odd number. This ensures that complete folia are accounted for and that there is no half-folio left dangling at the front or end of the group.
An Example
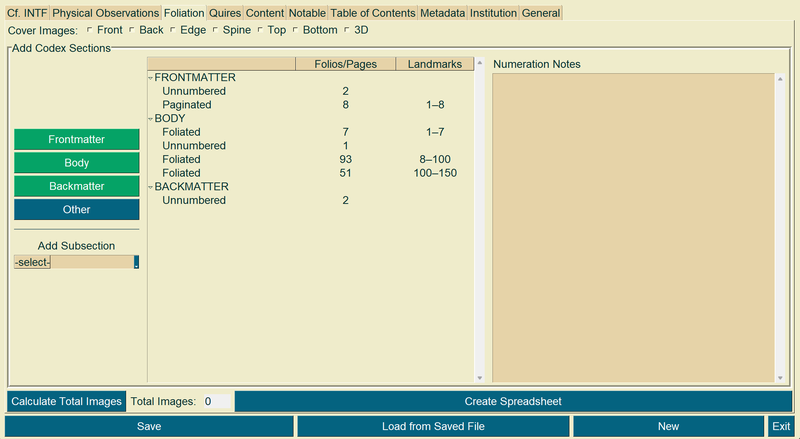
Let’s suppose that a book has the following structure.
- There are two flyleaves in the front.
- These are followed by a paginated section of frontmatter. The pagination is correct (i.e., it is consecutive with no skips or doubles). The first landmark of this section is “1” and the last is “8.”
- The main text begins on what would be page “9,” but the numbering starts over at “1” and it is foliated instead of paginated.
- The folio with the landmark “7” is followed by a folio with no written number which is then followed by a folio with the landmark “8.” (The human enumerator skipped a folio).
- Following landmark “8,” the foliation continues consecutively with no skips or doubles until landmark “100.”
- After the folio with “100” written on it, “100” is duplicated on the following folio.
- From there it proceeds consecutively until “150.”
- There are two flyleaves after “150.”
In my system, the above example would be notated as type: total/range
- Unnumbered: 2
- Paginated: 1-8
- Foliated: 1-7
- Unnumbered: 1
- Foliated: 8-100
- Foliated: 100-150
- Unnumbered: 2
Note how the groups go from type to type, or numeration mistake to numeration mistake. Within each group, the numeration is correct. My application can account for other situations, but these three numeration types will work for most New Testament Greek Manuscripts.
With this input, my application produces a spreadsheet with an image number for each image to be captured, the landmark of every page, and the running “actual” number correlated to the landmark. A separate application consumes this spreadsheet and hooks into our camera software to display a live count that continuously displays what should have just been captured, what should be captured now, and what should be captured next.
My goal is to get all of this information with minimal input. After being battle-tested by some bizarrely foliated/paginated manuscripts, it has proven to be a reliable tool that keeps the imaging team on track. At any point someone can call for a pause to check that the image number corresponds to correct the landmark to ensure that no pages have been skipped or duplicated.
Loose Ends
Someone is asking: What about manuscripts whose folia have not been numerated at all? Good question! There are different approaches.
- Slips of acid-free paper can be placed every 10 or 20 folia as a stand-in for landmarks.
- Landmarks need not be numbers. It is possible to record headings or first words of a page instead. The major drawback with this method, however, is that it leads to maximal input. Instead of using ranges to keep input minimal, every page is entered on a custom form.
- Quire numbers make good landmarks if the imaging team can read Greek numerals.
What about right-to-left scripts?
Little in my system needs to be adapted. I use recto and verso (right and left) instead of “front” and “back” for this very reason.
Is the software available?
It will be! I will release it free and open source soon. If this sounds especially useful to you, then I’d be happy to put a rush on the public release. Let me know.